

Many workloads nowadays involve many systems that operate concurrently. This ranges from microservice fleets to workflow orchestration to CI/CD pipelines. Sometimes it’s important to coordinate these systems so that concurrent operations don’t step on each other. One way to do that is by using distributed locks that work across multiple systems.
Distributed locks used to require complex algorithms or complex-to-operate infrastructure, making them expensive both in terms of costs as well as in upkeep. With the emergence of fully managed and serverless cloud systems, this reality has changed.
In this post I’ll look into a distributed locking algorithm based on Google Cloud. I’ll discuss several existing implementations and suggest algorithmic improvements in terms of performance and robustness.
Update: there is now a Ruby implementation of this algorithm!
Use cases for distributed locks
Distributed locks are useful in any situation in which multiple systems may operate on the same state concurrently. Concurrent modifications may corrupt the state, so one needs a mechanism to ensure that only one system can modify the state at the same time.
A good example is Terraform. When you store the Terraform state in the cloud, and you run multiple Terraform instances concurrently, then Terraform guarantees that only one Terraform instance can modify the infrastructure concurrently. This is done through a distributed lock. In contrast to a regular (local system) lock, a distributed lock works across multiple systems. So even if you run two Terraform instances on two different machines, then Terraform still protects you from concurrent modifications.
More generally, distributed locks are useful for ad-hoc system/cloud automation scripts and CI/CD pipelines. Sometimes you want your script or pipeline to perform non-trivial modifications that take many steps. It can easily happen that multiple instances of the script or pipeline are run. When that happens, you don’t want those multiple instances to perform the modification at the same time, because that can corrupt things. You can use a distributed lock to make concurrent runs safe.
Here’s a concrete example involving a CI/CD pipeline. Fullstaq Ruby had an APT and YUM repository hosted on Bintray. A few months ago, Bintray announced that they will shutdown in the near future, so we had to migrate to a different solution. We chose to self-host our APT and YUM repository on a cloud object store.
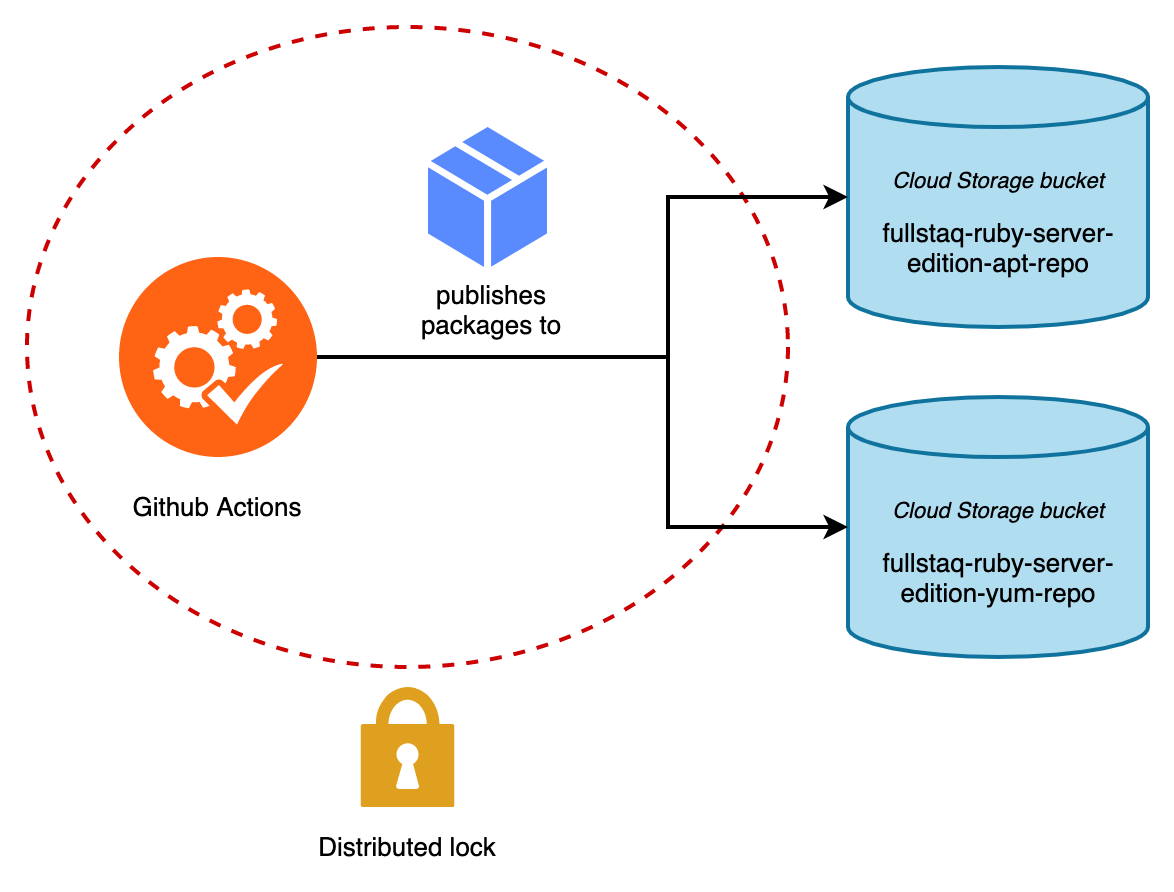
APT and YUM repositories consist of a bunch of .deb and .rpm packages, plus a bunch of metadata. Package updates are published through Fullstaq Ruby’s CI/CD system. This CI/CD system directly modifies multiple files on the cloud object store. We want this publication process to be concurrency-safe because if we commit too quickly then multiple CD/CD runs may occur at the same time. The easiest way to achieve this is by using a distributed lock, so that only one CI/CD pipeline may operate on the cloud object bucket concurrently.
Why building on Google Cloud Storage?
Distributed locks used to be hard to implement. In the past they required complicated consensus protocols such as Paxos or Raft, as well as the hassle of hosting yet another service. See Distributed lock manager.
In a more recent past, people started implementing distributed locks on top of other distributed systems, such as transactional databases and Redis. This significantly reduced the complexity of algorithms. But operational complexity was still significant. A big issue is that these systems aren’t “serverless”: operating and maintaining a database instance or a Redis instance is not cheap. It’s not cheap in terms of effort. It’s also not cheap in terms of costs: you pay for a database/Redis instance based on its uptime, not based on how many operations you perform.
Luckily, there are many cloud systems nowadays which not only provide the building blocks necessary to build a distributed lock, but are also fully managed and serverless. Google Cloud Storage is a great system to build a distributed lock on. It’s cheap, it’s popular, it’s highly available and it’s maintenance-free. You only pay for the amount of operations you perform on it.
Basic challenges of distributed locking
One of the problems that distributed locking algorithms need to solve, is the fact that participants in the algorithm need to communicate with each other. Distributed systems may run in different networks that aren’t directly connected.
Another problem is that of concurrency control. This is made difficult by communication lag. If two participants request ownership of a lock simultaneously, then we want both of them to agree on a single outcome even though it takes time for each participant to hear the other.
Finally, there is the problem of state consistency. When you write to a storage system, then next time you read from that system you want to read what you just wrote. This is called strong consistency. Some storage systems are eventually consistent, which means that it takes a while before you read what you just wrote. Storage systems that are eventually consistent are not suitable for implementing distributed locks.
This is why we leverage Google Cloud Storage as both a communication channel, and as a “referee”. Everyone can connect to Cloud Storage, and access control is simple and well-understood. Cloud Storage is also a strongly consistent system and has concurrency control features. This latter allows Cloud Storage to make a single, final decision in case two participants want to take ownership of the lock simultaneously.
Building blocks: generation numbers and atomic operations
Every Cloud Storage object has two separate generation numbers.
- The normal generation number changes every time the object’s data is modified.
- The metageneration number changes every time the object’s metadata is modified.
When you perform a modification operation, you can use the x-goog-if-generation-match/x-goog-if-metageneration-match headers in the Cloud Storage API to say: “only perform this operation if the generation/metageneration equals this value”. Cloud Storage guarantees that this effect is atomic and free of race conditions. These headers are called precondition headers.
The special value 0 for x-goog-if-generation-match means “only perform this operation if the object does not exist”.
This feature — the ability to specify preconditions to operations — is key to concurrency control.
Existing implementations
Several implementations of a distributed lock based on Google Cloud Storage already exist. A prominent one is gcslock by Marc Cohen, who works at Google. Gcslock leverages the x-goog-if-generation-match header, as described in the previous section. Its algorithm is simple, as we’ll discuss in the next section.
Most other implementations, such as gcs-mutex-lock and gcslock-ruby, use the gcslock algorithm though with minor adaptations.
I’ve been able to find one implementation that’s significantly different and more advanced: HashiCorp Vault’s leader election algorithm. Though it’s not functionally meant to be used as a lock, technically it boils down to a lock. We’ll discuss this algorithm in a later section.
Gcslock: a basic locking algorithm
The gcslock algorithm is as follows:
- Taking the lock means creating an object with
x-goog-if-generation-match: 0.- The content of the object does not matter.
- If creation is successful, then it means we’ve taken the lock.
- If creation fails with a 412 Precondition Failed error, then it means the object already exists. This means the lock was already taken. We retry later. The retry sleep time increases exponentially every time taking the lock fails.
- Releasing the lock means deleting the object.
This algorithm is very simple. It is also relatively high-latency because Cloud Storage’s response time is measured in tens to hundreds of milliseconds, and because it utilizes retries with exponential backoff. Relative high latency may or may not be a problem depending on your use case. It’s probably fine for most batch operations, but it’s probably unacceptable for applications that require pseudo-realtime responsiveness.
There are bigger issues though:
- Prone to crashes. If a process crashes while having taken the lock, then the lock becomes stuck forever until an administrator manually deletes the lock.
- Hard to find out who the owner is. There is no administration about who owns the mutex. The only way to find out who owns the lock is by querying the processes.
- Unbounded backoff. The exponential backoff has no upper limit. If the lock is taken for a long time (e.g. because a process crashed during a lock) then the exponential backoff will grow unbounded. This means that an administrator may need to restart all sorts of processes, after having deleted a stale lock.gcs-mutex-lock and gcslock-ruby address this by setting an upper bound to the exponential backoff.
- Retry contention. If multiple processes start taking the lock at the same time, then they all back off at the same rate. This means that they end up retrying at the same time. This causes spikes in API requests towards Google Cloud Storage. This can cause network contention issues.gcs-mutex-lock addresses this by allowing adding jitter to the backoff time.
- Unintended releases. A lock release request may be delayed by the network. Imagine the following scenario:
- An administrator thinks the lock is stale, and deletes it.
- Another process takes the lock.
- The original lock release request now arrives, inadvertently releasing the lock.
This sort of network-delay-based problem is even documented in the Cloud Storage documentation as a potential risk.
Resisting stuck locks via TTLs
One way to avoid stuck locks left behind by crashing processes, is by considering locks to be stale if they are “too old”. We can use the timestamps that Cloud Storage manages, which change every time an object is modified.
What should be considered “too old” really depends on the specific operation. So this should be a configurable parameter, which we call the time-to-live (TTL).
What’s more, the same TTL value should be agreed upon by all processes. Otherwise we’ll risk that a process thinks the lock is stuck even though the owner thinks it isn’t. One way to ensure that all processes agree on the same TTL is by configuring them with the same TTL value, but this approach is error-prone. A better way is to store the TTL value into the lock object.
Here’s the updated locking algorithm:
- Create the object with
x-goog-if-generation-match: 0.- Store the TTL in a metadata header.
- The content of the object does not matter.
- If creation is successful, then it means we’ve taken the lock.
- If creation fails with a 412 Precondition Failed error (meaning the object already exists), then:
- Fetch from its metadata the update timestamp, generation number and TTL.
- If the update timestamp is older than the TTL, then delete the object, with
x-goog-if-generation-match: [generation]. Specifying this header is important, because if someone else takes the lock concurrently (meaning the lock is no longer stale), then we don’t want to delete that. - Retry the locking algorithm after an exponential backoff (potentially with an upper limit and jitter).
What’s a good value for the TTL?
- Cloud Storage’s latency is relatively high, in the order of tens to hundreds of milliseconds. So the TTL should be at least a few seconds.
- If you perform Cloud Storage operations via the
gsutilCLI, then you should be aware that gsutil takes a few seconds to start. Thus, the TTL should be at least a few ten seconds. - A distributed lock like this is best suited for batch workloads. Such workloads typically take seconds to tens or even hundreds of seconds. Your TTL should be a safe multiple of the time your operation is expected to take. We’ll discuss this further in the next section, “long-running operations”.
As a general rule, I’d say that a safe TTL should be in the order of minutes. It should be at least 1 minute. I think a good default is 5 minutes.
Long-running operations
If an operation takes longer than the TTL, then another process could take ownership of the lock even though the original owner is still operating. Increasing the TTL addresses this issue somewhat, but this approach has drawbacks:
- If the operation’s completion time is unknown, then it’s impossible to pick a TTL.
- A larger TTL means that it takes longer for processes to detect stale locks.
A better approach is to refresh the object’s update timestamp regularly as long as the operation is still in progress. Keep the TTL relatively short, so that if the process crashes then it won’t take too much time for others to detect the lock as stale.
We implement refreshing via a PATCH object API call. The exact data to patch doesn’t matter: we only care about the fact that Cloud Storage will change the update timestamp.
We call the time between refreshes the refresh interval. A proper value for the refresh interval depends on the TTL. It must be much shorter than the TTL, otherwise refreshing the lock is pointless. Its value should take into consideration that a refresh operation is subject to network delays, or even local CPU scheduling delays.
As a general rule, I recommend a refresh interval that’s at most 1/8th of the TTL. Given a default TTL of 5 minutes, I recommend a default refresh interval of ~37 seconds. This recommendation takes into consideration that refreshes can fail, which we’ll discuss in the next section.
Refresh failures
Refreshing the lock can fail. There are two failure categories:
- Unexpected state
- The lock object could have been unexpectedly modified by someone else.
- The lock object could be unexpectedly deleted.
- Network problems
- If this means that the refresh operation is arbitrarily delayed by the network, then we can end up refreshing a lock that we don’t own. While this is unintended, it won’t cause any real problems.
- But if this means that the operation failed to reach Cloud Storage, and such failures persist, then the lock can become stale even though the operation is still in progress.
How should we respond to refresh failures?
- Upon encountering unexpected state, we should abort the operation immediately.
-
Upon encountering network problems, there’s a chance that the failure is just temporary. So we should retry a couple of times. Only if retrying fails too many times consecutively do we abort the operation.
I think retrying 2 times (so 3 tries in total) is reasonable. In order to abort way before the TTL expires, the refresh interval must be shorter than 1/3rd of the TTL.
When we conclude that we should abort the operation, we declare that the lock is in an unhealthy state.
Aborting should happen in a manner that leaves the system in a consistent state. Furthermore, aborting takes time, so it should be initiated way before the TTL expires, and it’s also another reason why in the previous section I recommended a refresh interval of 1/8th of the TTL.
Dealing with inconsistent operation states
Aborting the operation could itself fail, for example because of network problems. This may leave the system in an inconsistent state. There are ways to deal with this issue:
- Next time a process takes the lock, detect whether the state is inconsistent, and then deal with it somehow, for example by fixing the inconsistency.This means that the operation must be written in such a way that inconcistency can be detected and fixed. Fixing arbitrary inconsistency is quite hard, so you should carefully design the operation’s algorithm to limit how inconsistent a state can become.This is a difficult topic and is outside the scope of this article. But you could take inspiration from how journaling filesystems work to recover the filesystem state after a crash.
- An easier approach that’s sometimes viable, is to consider existing state to be immutable. Your operation makes a copy of the existing state, perform operations on the copy, then atomically (or at least nearly so) declare the copy as the new state.
Detecting unexpected releases or ownership changes
The lock could be released, or its ownership could change, at any time. Either because of a faulty process or because of an unexpected administrator operation. While such things shouldn’t happen, it’s still a good idea if we are able to handle them somehow.
When these things happen, we also say that the lock is in an unhealthy state.
We make the following changes to the algorithm:
- Right after having taken the lock, take note of its generation number.
- When refreshing the lock, use the
x-goog-if-generation-match: <last known generation number>header.- If it succeeds, take note of the new generation number.
- If it fails because the object does not exist, then it means the lock was deleted. We abort the operation.
- If it fails with a 412 Precondition Failed error, then it means the ownership unexpectedly changed. We abort the operation without releasing the lock.
- When releasing the lock, use the
x-goog-if-generation-match: <last known generation number>header, so that we’re sure we’re releasing the lock we owned and not one that was taken over by another process. We can ignore any 412 Precondition Failed errors.
Studying HashiCorp Vault’s leader election algorithm
HashiCorp Vault is a secrets management system. Its high availability setup involves leader election. This is done by taking ownership of a distributed lock. The instance that succeeds in taking ownership is considered the leader.
The leader election algorithm is implemented in physical/gcs/gcs_ha.go and was originally written by Seth Vargo at Google. This algorithm was also discussed by Ahmet Alp Balkan at the Google Cloud blog.
Here are the similarities between Vault’s algorithm and what we’ve discussed so far:
- Vault utilizes Cloud Storage’s precondition headers to find out whether it was successful in taking a lock.
- When Vault fails to take a lock, it also retries later until it suceeds.
- Vault detects stale locks via a TTL.
- Vault refreshes locks regularly. A Vault instance holds on to the lock as long as its willing to be the leader, so we can consider this to be a gigantic long-running operation, making lock refreshing essential.
- Vault checks regurlarly whether the lock was unexpectedly released or changed ownership.
- When Vault releases the lock, it also uses a precondition header to ensure it doesn’t delete a lock that someone else took ownership of concurrently.
Notable differences:
- Vault checks whether the lock is stale, before trying to create the lock object. Whereas we check for staleness after trying to do so. Checking for staleness afterwards is a more optimistic approach. If the lock is unlikely to be stale, then checking afterwards is faster.
- When Vault fails to take the lock, it backs off linearly instead of exponentially.
- Instead of checking the generation number, and refreshing the lock by updating its data, Vault operates purely on object metadata because it’s less costly to read frequently. This means the algorithm checks the metageneration number, and refreshes the lock by updating metadata fields.
- Vault stores its unique instance identity name in the lock. This way administrators can easily find out who owns the lock.
- Vault’s TTL is a runtime configuration parameter. Its value is not stored in the object.
-
If Vault’s leader election system crashes non-fatally (e.g. it detected an unhealthy lock, aborted, then tried again later from the same Vault instance), and the lock hasn’t been taken over by another Vault instance at the same time, then Vault is able to retake the lock instantly.
In contrast, our approach so far requires waiting until the lock becomes stale per the TTL.
I think points 3, 4 and 6 are worth learning from.
Instant recovery from stale locks & thread-safety
HashiCorp Vault’s ability to retake the lock instantly after a non-fatal crash is worthy of further discussion. It’s a desirable feature, but what are the implications?
Upon closer inspection, we see that this feature works by assigning an identity to the lock object. This identity is a random string that’s generated during Vault startup. When Vault attempts to take a lock, it checks whether the object already exists and whether its identity equals the Vault instance’s own identity. If so, then Vault concludes that it’s safe to retake the lock immediately.
This identity string must be chosen with some care, because it affects on the level of mutual exclusion. Vault generates a random identity string that’s unique on a per-Vault-instance basis. This results in the lock being multi-process safe, but — perhaps counter-intuitively — not thread-safe!
We can make the lock object thread-safe by including the thread ID in the identity as well. The tradeoff is that an abandoned lock can only be quickly recovered by the same thread that abandoned it in the first place. All other threads still have to wait for the TTL timeout.
In the next section we’ll put together everything we’ve discussed and learned so far.
Putting the final algorithm together
Taking the lock
Parameters:
- Object URL
- TTL
- An identity that’s unique on a per-process basis, and optionally on a per-thread basis as well
- Example format: “[process identity]”. If thread-safety is desired, append “/[thread identity]”.
- Interpret the concept “thread” liberally. For example, if your language is single-threaded with cooperative multitasking using coroutines/fibers, then use the coroutine/fiber identity.
Steps:
- Create the object at the given URL.
- Use the
x-goog-if-generation-match: 0header. - Set Cache-Control: no-store
- Set the following metadata values:
- Expiration timestamp (based on TTL)
- Identity
- Empty contents.
- Use the
- If creation is successful, then it means we’ve taken the lock.
- Start refreshing the lock in the background.
- If creation fails with a 412 Precondition Failed error (meaning the object already exists), then:
- Fetch from the object’s metadata:
- Update timestamp
- Metageneration number
- Expiration timestamp
- Identity
- If step 1 fails because the object didn’t exist, then restart the algorithm from step 1 immediately.
- If the identity equals our own, then delete the object, and immediately restart the algorithm from step 1.
- When deleting, use the
x-goog-if-metageneration-match: [metageneration]header.
- When deleting, use the
- If the update timestamp is older than the expiration timestamp then delete the object.
- Use the
x-goog-if-metageneration-match: [metageneration]header.
- Use the
- Otherwise, restart the algorithm from step 1 after an exponential backoff (potentially with an upper limit and jitter).
- Fetch from the object’s metadata:
Releasing the lock
Parameters:
- Object URL
- Identity
Steps:
- Stop refreshing the lock in the background.
- Delete the lock object at the given URL.
- Use the
x-goog-if-metageneration-match: [last known metageneration]header. - Ignore the 412 Precondition Failed error, if any.
- Use the
Refreshing the lock
Parameters:
- Object URL
- TTL
- Refresh interval
- Max number of times the refresh may fail consecutively
- Identity
Every refresh_interval seconds (until a lock release is requested, or until an unhealthy state is detected):
- Update the object metadata (which also updates the update timestamp).
- Use the
x-goog-if-metageneration-match: [last known metageneration]header. - Update the expiration timestamp metadata value, based on the TTL.
- Use the
- If the operation succeeds, check the response, which contains the latest object metadata.
- Take note of the latest metageneration number.
- If the identity does not equal our own, then declare that the lock is unhealthy.
- If the operation fails because the object does not exist or because of a 412 Precondition Failed error, then declare that the lock is unhealthy.
- If the operation fails for some other reason, then check whether this is the maximum number of times that we may fail consecutively. If so, then declare that the lock is unhealthy.
Recommended default values
- TTL: 5 minutes
- Refresh interval: 37 seconds
- Max number of times the refresh may fail consecutively: 3
Lock usage
Steps:
- Take the lock
- Try:
- If applicable:
- Check whether state is consistent, and fix it if it isn’t
- Check whether lock is healthy, abort if not
- Perform a part of the operation
- Check whether lock is healthy, abort if not
- …etc…
- If applicable: commit the operation’s effects as atomically as possible
- If applicable:
- Finally:
- Release the lock
Conclusion
Distributed locks are very useful for ad-hoc system/cloud automation scripts and CI/CD pipelines. Or more generally, they’re useful in any situation in which multiple systems may operate on the same state concurrently. Concurrent modifications may corrupt the state, so one needs a mechanism to ensure that only one system can modify the state at the same time.
Google Cloud Storage is a good system to build a distributed lock on, as long as you don’t care about latency that much. By leveraging Cloud Storage’s capabilities, we can build a robust distributed locking algorithm that’s not too complex. What’s more: it’s cheap to operate, cheap to maintain, and can be used from almost anywhere.
The distributed locking algorithm proposed by this article builds upon existing algorithms found in other systems, and makes locking more robust.
Eager to use this algorithm in your next system or pipeline? Check out the Ruby implementation. In the near future I also plan on releasing implementations in other languages.




