

Containers are no longer only used on servers. They are increasingly used on the desktop: as CLI apps or as development environments. I call this the “container-as-OS-app” use case. Within this use case, containerized apps often generate files that are not owned by your local machine’s user account. Sometimes they can’t access files on the host machine at all. This is the host filesystem owner matching problem.
- This is bad for security. Containers shouldn’t run as root in the first place!
- This is a potential productivity killer. It’s annoying having to deal with wrong file permissions!
Solutions are available, but they have major caveats. As a result it’s easy to implement a solution that only works for some, but not everyone. “It works on my machine” is kind of embarrassing when you distribute a development environment to a coworker, who then runs into issues.
This post describes what causes the host filesystem owner matching problem, and analyzes various solutions and their caveats.
What is the “container-as-OS-app” use case?
An “OS app” is an app that:
- Runs on your machine (as opposed to in the browser or on a server).
- Reads or writes files from/to the host OS filesystem. Files which later may be read/written by other (non-Docker-packaged) apps, such your text editor.
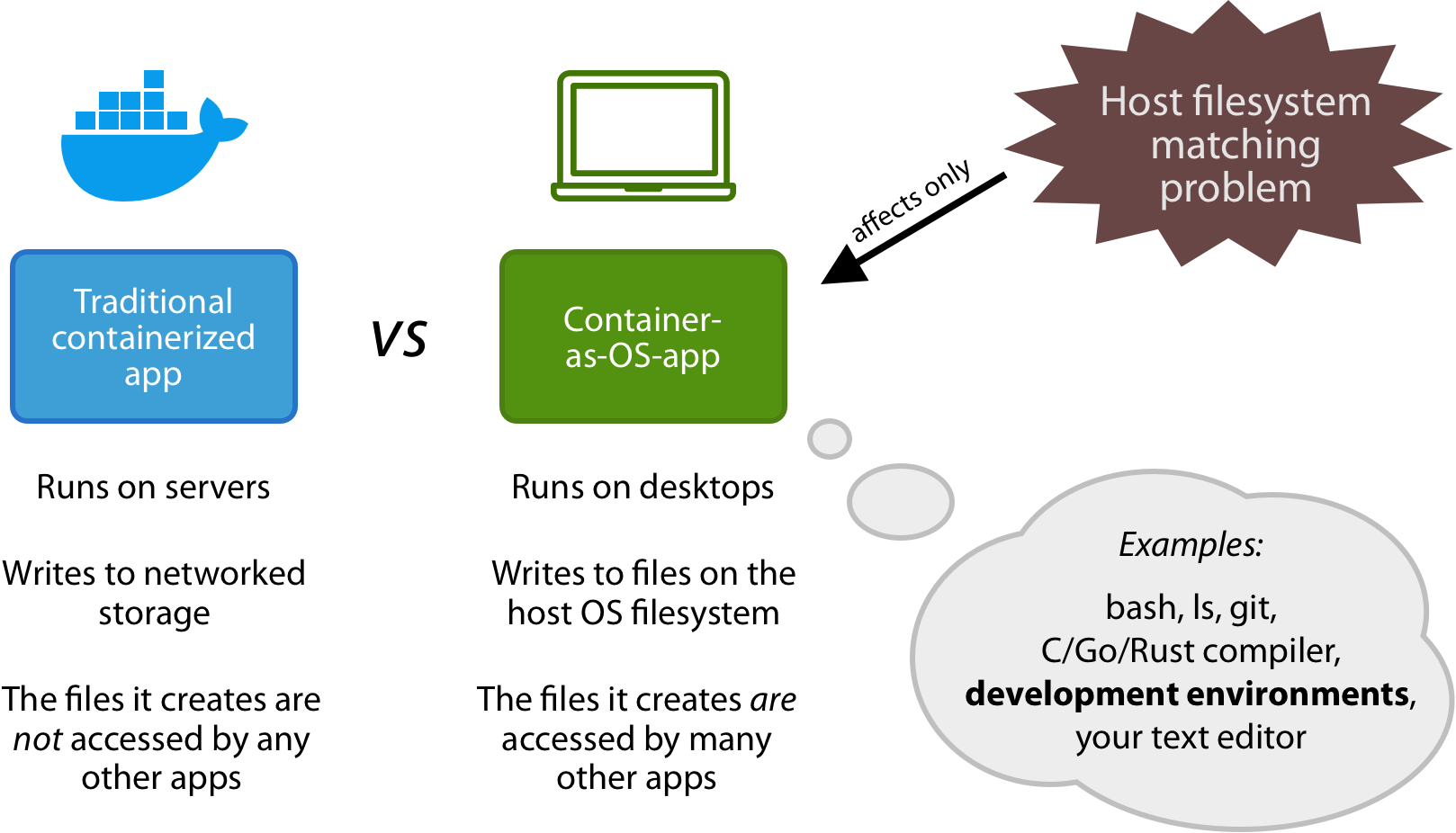
An OS app doesn’t have to be graphical in nature. In fact, the kind of OS apps that are often containerized, are CLIs. Examples of OS apps:
- bash
- ls
- Git
- The C/Go/Rust compiler
- Your text editor
Increasingly, Docker is used to package such apps. Here are a few examples:
- rust-musl-builder — compilation environment for Rust that allows generating statically-linked binaries.
- Holy Build Box — compilation environment for C/C++ that allows generating portable Linux binaries that run on any Linux distribution.
Both of these examples read or write files from/to the host OS filesystem.
Perhaps a little counter-intuitively, many development environments often also fall under this category. Let’s say that you setup a development environment for your Ruby, Node.js or Go app, using Docker-Compose. Here’s what such a Docker-Compose environment often does:
- It mounts the project directory (on the host filesystem) into the container.
- (In case of compiled languages:) Inside the container, it compiles the source code located in the project directory. The compilation products, or cache files, are stored under the project directory.
- Inside the container, it launches the app, which runs until the user requests abortion.
- (For frameworks/languages where this is applicable:) If the source code on the host OS changes, then the app inside the container live-reloads the new code.
- The app inside the container writes to log files, located under the project directory.
Key takeaway: development environments often read or write files from/to the host OS filesystem. Files which may be read/written by other apps later.
Mismatching filesystem owners
Many containers run apps as root. When they write to files on the host filesystem, they create root-owned files on your host filesystem. You can’t modify these files with your host text editor without jumping through some hoops.
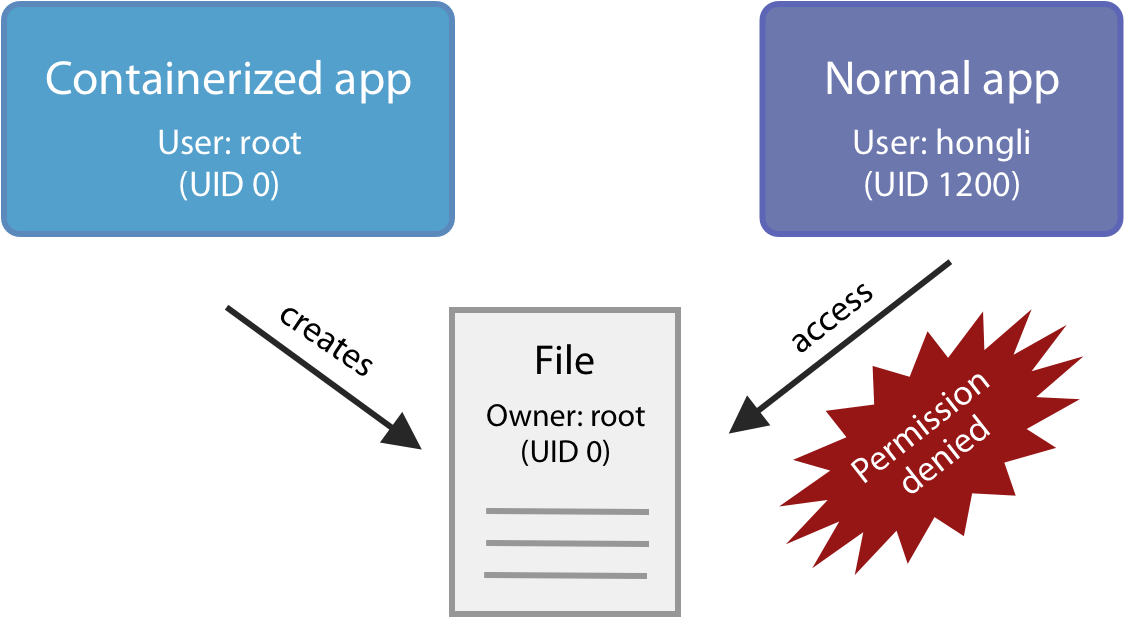
For example: on a Linux machine (not on macOS; see below), let’s run a root container which writes a file on the host:
docker run --rm -v "$(pwd):/host" busybox touch /host/foo.txt
This file is owned by root, and we can’t modify it:
$ ls -l foo.txt
-rw-r--r-- 1 root root 0 Jan 17 10:36 foo.txt
$ echo hi > foo.txt
-bash: foo.txt: Permission denied
Some containers adhere to better security practices, and run under a normal user account. However, this creates a new problem: they can’t write to the host filesystem anymore! This is because the host directory is only writable by the user who owns it, not by the user inside the container.
Here’s an example container that runs under a normal user account instead of root:
FROM debian:10
RUN addgroup --gid 1234 app && \
adduser --uid 1234 --gid 1234 --gecos "" --disabled-password app
USER app
We then build and run it, telling it to create a file on the host:
$ docker build . -t usercontainer
$ docker run --rm -v "$(pwd):/host" usercontainer touch /host/foo.txt
touch: cannot touch `/host/foo.txt': Permission denied
Only on Linux, not on macOS
These problems are only applicable when using Docker on Linux. macOS users don’t experience these problems at all, because Docker for Mac actually runs a Linux VM, and inside that VM it mounts host filesystems into the container as a network volume. It ensures that:
- Inside the container, all mounted files look as if they’re owned by the container user.
- On the host, all files written by the container become owned by the host user.
But the fact that macOS users don’t get this problem, is in itself a problem. It means that when someone creates a container-as-OS-app on macOS, and hands it over to a Linux user, then that app may not work because of the permission problems described above.
Solution strategies overview
There are two major strategies to solve the host filesystem owner matching problem:
- Matching the container’s UID/GID with the host’s UID/GID.
- Remounting the host path in the container using BindFS.
Each strategy has significant caveats. Let’s take a look at how each strategy is implemented, and what the caveats are.
Strategy 1: matching the container’s UID/GID with the host’s
The kernel distinguishes users and groups by two numbers: the user ID (UID) and the group ID (GID). Accounts (usernames and group names) are implemented outside the kernel, via user/group account databases that map UIDs and GIDs to usernames and group names. These databases exist in /etc/passwd and /etc/group.
The kernel doesn’t care about names, only about UIDs and GIDs. Even files on the filesystem are not owned by usernames or group names, but by UIDs and GIDs.
So if we run an app in a container using the the same UID/GID as the host account’s UID/GID, then the files created by that app will be owned by the host’s user and group.
- If the container’s user/group account database already has accounts with that UID/GID, but with a different name, then that’s no problem.
- If the container’s account database doesn’t have accounts with that UID/GID, then that’s also no problem.
The simplest way to do this is by running docker run --user <HOST UID>:<HOST GID>. This works even if the container has no accounts with this UID/GID.
However, if there are no matching accounts in the container, then many applications won’t behave well. This can range from cosmetic problems to crashes. A lot of library code assumes that the username can be queried, and abort on failure. Another problem is that the lack of accounts also mean that there’s also no corresponding home directory. A lot of application and library code assume that they can read from or write to the home directory.
So a better way would be to create accounts inside the container with a UID/GID that matches the host’s UID/GID. These accounts could have any names: the kernel doesn’t care.
Let’s go through a practical example to learn how container UIDs/GIDs and accounts work, and how to implement this strategy.
Example: creating a container account with the same UID/GID as the host account
Here’s an example which shows how UIDs and GIDs work. This example must be run on Linux (because you won’t run into the host filesystem owner matching problem on macOS). Let’s start by figuring out what the host user’s UID/GID is by running this command:
hongli@host$ id
uid=1000(hongli) gid=1000(hongli) groups=1000(hongli),27(sudo),999(docker)
My UID and GID are both 1000.
Now let’s start an interactive Debian shell session. We mount the host’s current working directory into the container, under /host.
docker run -ti --rm -v "$(pwd):/host" debian:10
Inside the Debian container’s root shell, let’s create two things:
- A group called
matchinguser, with GID 1000. - A user account called
matchinguserwith UID 1000. We disable the password because it’s not relevant in this example.
addgroup --gid 1000 matchinguser
adduser --uid 1000 --gid 1000 --gecos "" --disabled-password matchinguser
Let’s use this user account to create a file in the host directory:
apt update
apt install -y sudo
sudo -u matchinguser -H touch /host/foo2.txt
If we inspect the file permissions of /host/foo2.txt from inside the container, then we see that it’s owned by matchinguser:
root@container:/# ls -l /host/foo2.txt
-rw-r--r-- 1 hostuser hostuser 0 Mar 15 09:45 /host/foo2.txt
But if we inspect the same file from the host, then we see that it’s owned by the host user:
hongli@host:/# ls -l foo2.txt
-rw-r--r-- 1 hongli hongli 0 Mar 15 09:45 /host/foo2.txt
This is because the file has the UID and GID 1000, which in the container maps to matchinguser, but on the host maps to hongli.
Example: modifying existing container account’s UID
You don’t even have to create new container accounts. You can actually modify the UID/GID of existing accounts.
For example, let’s delete matchinguser, and recreate it with UID/GID 1500:
apt install -y perl # needed by deluser on Debian
deluser --remove-home matchinguser
addgroup --gid 1500 matchinguser
adduser --uid 1500 --gid 1500 --gecos "" --disabled-password matchinguser
We can then use usermod and groupmod to change those accounts’ UID/GID to 1000:
groupmod --gid 1000 matchinguser
usermod --uid 1000 matchinguser
Implementation and caveats
Here’s a simple implementation strategy. If your container doesn’t need precreated accounts, then you can do it as follows:
- Add an entrypoint script which creates a user/group account, whose UID/GID equal the host account’s UID/GID.
- The entrypoint script requires two environment variables,
HOST_UIDandHOST_GID, which specify what the host account’s UID and GID are. - The entrypoint then executes the next container command, under the newly created user/group accounts.
- Users must run the container with root privileges, with the environment variables
HOST_UIDandHOST_GID. The container is responsible for dropping privileges.
If your container requires a precreated account, then you need to modify the strategy a little bit:
- Instead of creating a new account, the entrypoint script modifies the UID/GID of the precreated user account, to the host account’s UID/GID.
Here’s an example of a naive entrypoint script. The container account that we want to use is called app.
#!/usr/bin/env bash
set -e
if [[ -z "$HOST_UID" ]]; then
echo "ERROR: please set HOST_UID" >&2
exit 1
fi
if [[ -z "$HOST_GID" ]]; then
echo "ERROR: please set HOST_GID" >&2
exit 1
fi
# Use this code if you want to create a new user account:
addgroup --gid "$HOST_GID" matchinguser
adduser --uid "$HOST_UID" --gid "$HOST_GID" --gecos "" --disabled-password app
# -OR-
# Use this code if you want to modify an existing user account:
groupmod --gid "$HOST_GID" app
usermod --uid "$HOST_UID" app
# Drop privileges and execute next container command, or 'bash' if not specified.
if [[ $# -gt 0 ]]; then
exec sudo -u -H app -- "$@"
else
exec sudo -u -H app -- bash
fi
The above entrypoint script is a good attempt, but fails to consider these significant caveats:
- What if there’s already another container user/group, with the same UID/GID as the host UID/GID?
Then it’s not possible to create a new user account/group with the host UID/GID.
One way to deal with this is by deleting the conflicting container user/group. However, depending on which account exactly is deleted (and what that account is used for inside the container), this could degrade the behavior of the container in unpredictable ways.
As a general rule of thumb, accounts with UID < 1000, and groups with GID < 1000, are considered system accounts and groups. System accounts/groups are managed by the OS maintainers, and are not supposed to be messed with by users of the OS.
In contrast, accounts/groups with UID/GID >= 1000 are “normal accounts”/”normal groups”, not managed by the OS maintainers. Users of the OS are free to do whatever they like with those accounts. But here you have to ask yourself: who, in this context, are “users of the OS”? If it’s only yourself, and you have full control over which normal accounts go into your container: then there’s no problem. But if you’re using a base image supplied by someone else, and the base image already comes with precreated normal accounts, then you have to ask yourself whether it’s safe to modify them.
- What if the host user is root?
The host user being root (with UID 0) is a special case that you need to deal with. It’s not a good idea to delete the existing root account in the container and replace it with another account. So if the entrypoint script detects that the host UID is 0, then it should run the next command as root.
But on weird systems, the host’s root user could have a non-zero GID! So if the entrypoint script detects that the UID is 0 but GID is non-zero, then should modify the root group’s GID. This in turn could run into the problem described by (1): what if there’s already another group with the same GID?
- In case of precreated accounts: what about the files it owned?
If your container makes use of a precreated account, then after you modify that account’s UID and GID, you should ask yourself what you should do about files that were owned by that account. Should those files’ UID/GID be updated to match the new UID/GID?
The Debian version of
usermod --uidautomatically updates the UIDs of all files in that account’s home directory (recursively). However,groupmoddoes not update the GIDs, so you need to do that yourself from your entrypoint script.usermod --uiddoes not update the UIDs of files outside that account’s home directory. It’s up to your entrypoint script to update those files, if any.Furthermore, you should ask yourself whether it’s a good idea to update the UIDs of those files. If those files are world-readable, and your container never writes them, then updating their UIDs/GIDs is redundant. If there are many files, then updating their UIDs/GIDs can take a significant amount of time. I ran into this very problem when using rust-musl-builder. Rust was installed via
rustupinto the home directory, and updating the UIDs/GIDs of~/.rustuptakes a lot of time.Perhaps it’s only necessary to update the UIDs/GIDs of only specific files. For example, only the files immediately in the home directory, not recursively. This must be judged on a per-container basis.
Finally, some Linux kernel versions have bugs in OverlayFS. Updating the UIDs/GIDs of existing files doesn’t always work. This can be worked around by making a copy of those files, removing the original files, and renaming the copies to their original names.
- Requires root privileges
The simple example entrypoint script is responsible for creating and modifying accounts, which requires root privileges. It’s also responsible for dropping privileges to a normal account. However, this means that we can’t use the
USERstanza in the Dockerfile. Furthermore, users can’t run the container with the--userflag, which is counter-intuitive and may make some users wary about the container’s security.One solution is to make the entrypoint program a setuid root executable. This means turning on the “setuid filesystem bit” on the entrypoint program, so that when the entrypoint program runs, it gains root privileges, even if the program was started by a non-root user.
The setuid bit is only used by a few select programs that are involved in privilege escalation. For example, Sudo uses the setuid bit. As you can imagine, the setuid bit is very dangerous. When not careful enough, anyone can gain root privileges without authentication. A setuid root program must be specifically written make abuse impossible.
Another complication is that the setuid root bit does not work on shell scripts, only on “real” executables! So if you want to make use of this bit, you’ll have to write the entrypoint program in a language that compiles to native executables, like C, C++, Rust or Go.
Under what conditions is it safe to run a setuid root entrypoint program? One answer is: if the entrypoint’s PID is 1. This means it’s the very first program run in the container. This indicates that the entrypoint program is run directly by
docker run, so we can assume that it’s a safe-ish environment.But checking for PID 1 doesn’t work in combination with
docker run --init, which spawns an init process (whose job is to solve the PID 1 zombie reaping problem). The init process can perform arbitrary work, and execute arbitrary processes before it executes our entrypoint program. So we can’t can’t assume that our PID is 2 either. Instead, we can check whether we’re a child process of the init process. Because after the init process executes the next command, it won’t execute any further commands. - Requires extra environment variables
In the ideal world, we want users to be able to run our container with
docker run --user HOST_UID:HOST_GID, and have the container’s entrypoint automatically figure out that the values passed to--userare the host UID/GID.But our example entrypoint script requires the user to specify that information through environment variables. So users have to pass redundant parameters, like this:
This is not a good user experience.docker run \ -e HOST_UID="$(id -u)" \ -e HOST_GID="$(id -g)" \ --user "$(id -u):$(id -g)" \ ...
With the above caveats, the entrypoint script becomes no longer trivial. If you want to solve caveat 4, then the entrypoint can’t even be a shell script anymore.
Strategy 2: remounting the host path in the container using BindFS
BindFS is a FUSE filesystem that allows us to mount a directory in another path, with different filesystem permissions. BindFS doesn’t change the original filesystem permissions: it just exposes an alternative view that looks as if all the permissions are different.
So a container can use BindFS to create an alternative view of the host directory. In this alternative view, everything is owned by a normal account in the container (whose UID/GID doesn’t have to match the host’s). When the container uses that account to write to the alternative view, then the created files are still owned by the original directory’s owner.
Thus, BindFS allows two-way mapping between the host’s UID/GID and the container’s UID/GID, in a way that’s transparent to applications.
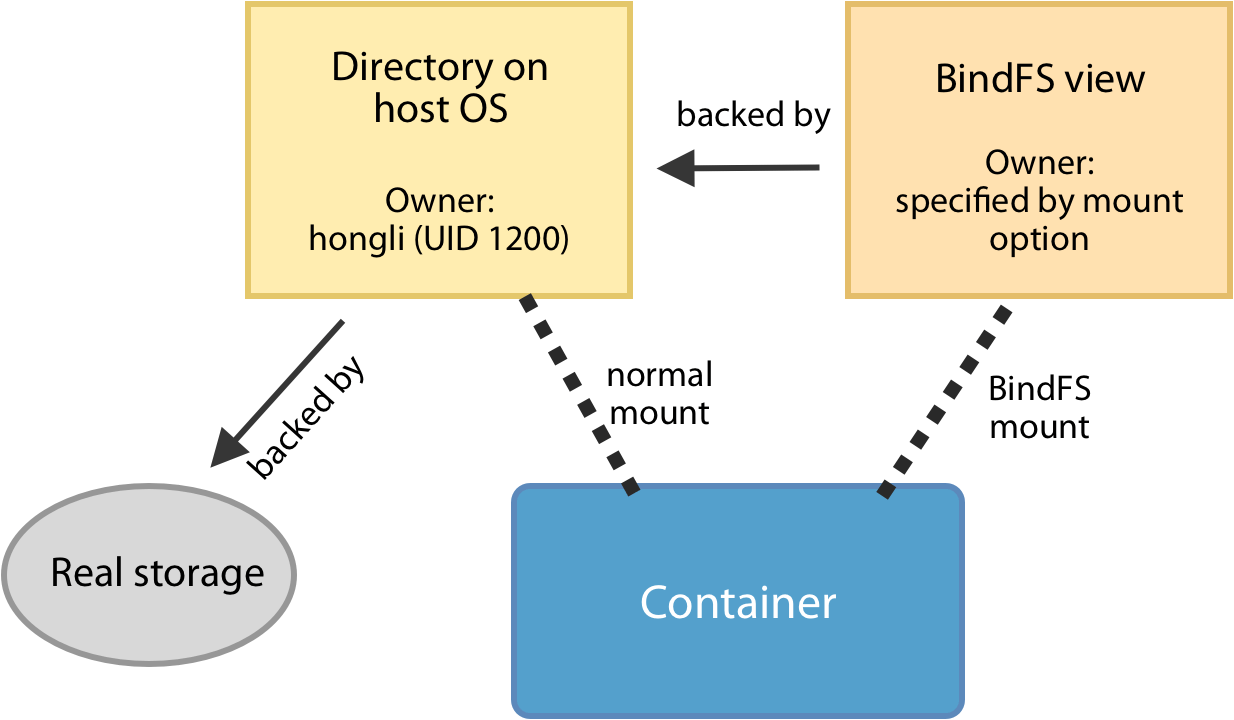
BindFS in action
Let’s take a look at how BindFS works. Remember: this example must be run on Linux, because the host filesystem owner matching problem does not appear on macOS.
First, let’s figure out what the host user’s UID/GID is:
hongli@host$ id
uid=1000(hongli) gid=1000(hongli) groups=1000(hongli),27(sudo),999(docker)
Next, run a Debian 10 container that mounts the current working directory into /host in the container. Be sure to pass --privileged so that FUSE works.
docker run -ti --rm --privileged -v "$(pwd):/host" debian:10
Once you’re in the container, install BindFS:
apt update
apt install -y bindfs
Next, create a user account in the container to play with:
addgroup --gid 1234 app
adduser --uid 1234 --gid 1234 --gecos "" --disabled-password app
Let’s use BindFS to mount /host to /host.writable-by-app.
mkdir /host.writable-by-app
bindfs --force-user=app --force-group=app --create-for-user=1000 --create-for-group=1000 --chown-ignore --chgrp-ignore /host /host.writable-by-app
Here’s what the flags mean:
--force-user=appand--force-group=appmean: make everything in /host look as if they’re owned by the user/group namedapp.--create-for-user=1000and--create-for-group=1000mean: when a new file is created, make it owned by UID/GID 1000 (the host’s UID/GID).--chown-ignoreand--chgrp-ignoremean: ignore requests to change a file’s owner/group. Because we want all files to be owned by the host’s UID/GID.
When you look at the permissions of the two directories, you see that one is owned by the host’s UID/GID, and the other by app:
root@container:/# ls -ld /host /host.writable-by-app
drwxr-xr-x 18 1000 1000 4096 Mar 15 10:10 /host
drwxr-xr-x 18 app app 4096 Mar 15 10:10 /host.writable-by-app
Let’s see what happens if we use the app account to create a file in both directories. First, install sudo:
apt install -y sudo
Then:
root@container:/# sudo -u app -H touch /host/foo3.txt
touch: cannot touch '/host/foo3.txt': Permission denied
root@container:/# sudo -u app -H touch /host.writable-by-app/foo3.txt
Creating a file in /host doesn’t work: app doesn’t have permissions. But creating a file in /host.writable-by-app does work.
If you look at the file in /host.writable-by-app, then you see that it’s owned by app:
root@container:/# ls -l /host.writable-by-app/foo3.txt
-rw-r--r-- 1 app app 0 Mar 16 11:06 /host.writable-by-app/foo3.txt
But if you look at the file in /host, then you see that it’s owned by the host’s UID/GID:
root@container:/# ls -l /host/foo3.txt
-rw-r--r-- 1 1000 1000 0 Mar 16 11:06 /host/foo3.txt
This is corroborated by the host. If you exit the container and look at foo3.txt, then you see that it’s owned by the host’s user:
hongli@host$ ls -l foo3.txt
-rw-r--r-- 1 hongli hongli 0 Mar 16 12:06 foo3.txt
Implementation
A container that wishes to use the BindFS strategy should have the necessary tools installed, and should include a precreated normal user account. For example:
FROM debian:10
ADD entrypoint.sh /
RUN apt update && \
apt install bindfs sudo && \
addgroup --gid 1234 app && \
adduser --uid 1234 --gid 1234 --gecos "" --disabled-password app
ENTRYPOINT ["/entrypoint.sh"]
Then:
docker build . -t bindfstest
The entrypoint script could be as follows. In this example, the entrypoint script assumes that the container is started with /host being mounted to a host directory.
#!/usr/bin/env bash
set -e
if [[ -z "$HOST_UID" ]]; then
echo "ERROR: please set HOST_UID" >&2
exit 1
fi
if [[ -z "$HOST_GID" ]]; then
echo "ERROR: please set HOST_GID" >&2
exit 1
fi
mkdir /host.writable-by-app
bindfs --force-user=app --force-group=app \
--create-for-user=1000 --create-for-group=1000 \
--chown-ignore --chgrp-ignore \
/host /host.writable-by-app
# Drop privileges and execute next container command, or 'bash' if not specified.
if [[ $# -gt 0 ]]; then
exec sudo -u -H app -- "$@"
else
exec sudo -u -H app -- bash
fi
The container is then run as follows:
docker run -ti --rm --privileged \
-v "/some-host-path:/host" \
-e "HOST_UID=$(id -u)" \
-e "HOST_GID=$(id -g)" \
bindfstest
Caveats
BindFS works very well. But there are two caveats:
- It requires privileged mode! Because FUSE requires this. This might be a security concern.
- The container cannot be started as non-root! Although it’s possible to work around this problem by using a setuid root entrypoint program, as is described in strategy 1 caveat 4.
Some Internet sources say that that --privileged can be replaced with --device /dev/fuse --cap-add SYS_ADMIN. However:
SYS_ADMINcapabilities is not much better than--privilegedfrom a security perspective.- This trick doesn’t work on Docker for Mac. It results in an error.
Conclusion
There are two major strategies to solve the host filesystem owner matching problem:
- Matching the container’s UID/GID with the host’s UID/GID.
- Remounting the host path in the container using BindFS.
Both strategies have their own benefits and drawbacks.
- Using BindFS is easy to implement by yourself, but requires starting the container with root privileges, and in privileged mode.
- Running the container in a matching UID/GID does not require privileged mode. It also allows the container to run without root privileges. But it is hard to implement if you want to address all caveats.
BindFS’s caveats can’t be solved. But the caveats related to “matching the container UID/GID with the host’s” can be solved, even if it takes quite a lot of engineering.
Armed with the knowledge provided by this article, you’ll be able to build a solution yourself. But wouldn’t it be nice if you can use a solution already made by someone else — especially if that solution uses strategy 1, which is hard to implement? Stay tuned for the next article, where we’ll introduce such a solution!
Originally published on Joyful Bikeshedding.
The Docker icon used in this article’s illustrations is made by Flatart.




