

We have used pipelines for the regular implementation of CI/CD principles for years, but we have come to a point where splitting CI from CD makes a lot of sense. Have you ever had to rethink your standard pipelines because it was growing in complexity and difficulty? In this blog, I go into the differences between CI and CD in the often-used acronym CI/CD. This blog is the first in a series of blogs on how to rethink standard pipelines into something more futureproof.
What is CI/CD?
First, let's go over the basics. What is CI/CD (Continuous Integration / Continuous Delivery / Deployment)? In our day-to-day jobs, we use the term CI/CD as a synonym for pipelines. But let's find out what the two parts are to CI/CD.
CI stands for Continuous Integration, and CD stands for Continuous Deployment or Continuous Delivery. Just like the term DevOps, CI/CD can mean multiple things. It depends on if you talk to a developer who might see it as Continuous Integration and Continuous Delivery, where an infrastructure engineer might think of Continuous Integration and Continuous Deployment.
For this discussion, we treat CD as Continuous Deployment.
Let's look at a regular pipeline to help us understand the difference between CI and CD.

In the above example pipeline, we have a trigger that triggers on a code change. Whenever the code changes it:
- Tests the code with, for instance, Unit Tests
- Builds the code to deliver an artifact
- Package and Publish the artifact to, for example, a container registry.
- Deploy the artifact to the servers
- Configure the artifact on the servers
- (Re)Start the software to bring the new version live.
Obviously, not all steps are always valid. For instance, Python code does not require any building. But in general, these are the steps that apply to most software pipelines.
In practice, everything up to the Deploy step falls under the CI umbrella. This means everything except for the actual management of the built artifact on the end servers.
CD then covers managing deployment, configuration, and ensuring the software is running on the actual servers.
What changed?
In ye olde times, the difference was usually what developers and DevOps engineers would do. Seems fine, right? We push code. It automatically gets built and published and even automatically started and configured for the environment it needs to run on! So what is the problem?!
Well, one issue we can immediately see is that these pipelines are actually quite complex! These pipelines need access to all the environment-specific information and host the steps to build and deploy the code. Generally, these steps are very dissimilar to each other.
The often growing complexity of these pipelines can lead to difficulty in maintaining them and makes adding new functionality impactful.
But wait, there's more!
The steps defined in the generic pipeline are fine. In fact, they are needed to run any kind of software, whether you do it manually or automatically.
Let's have a look at what most Git repositories look like.
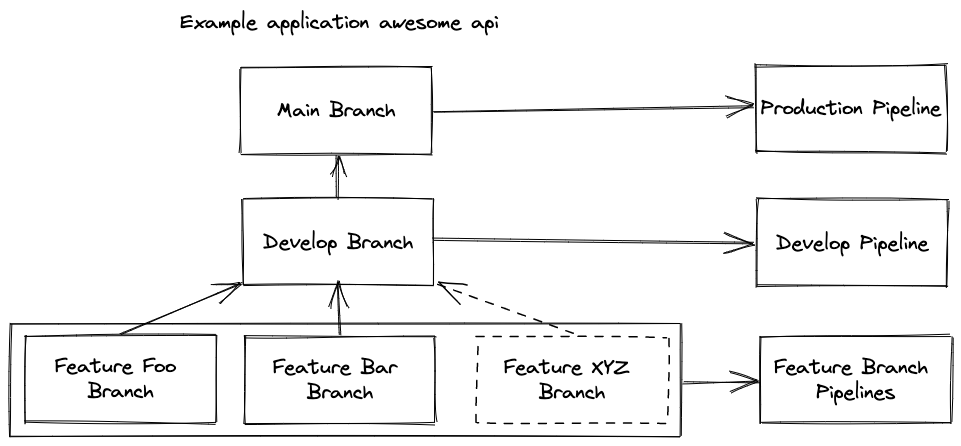
We have three types of branches here.
Main Branch
The main branch is synonymous with the production environment. Code pushed here goes to production and should only be merged when the code has been vetted on a different environment first.
Develop Branch
A placeholder really for any environment-specific branch. This branch means that code pushed here immediately goes to the development environment. It then enables someone to check the development environment and decide if the code is ready for production.
Feature Branch (or bugfix branches)
Feature branches are where developers do their work. They open a new branch, start working on a new feature or bugfix and push their code. This pipeline would usually only test the code. Maybe, if you're really fancy, deploy it to a develop environment specific for that one feature branch.
So it's already becoming more complex. We don't just have one pipeline. We have one pipeline template that will look and behave differently depending on which branch (or git tag) is used.
What do most CI/CD solutions look like?
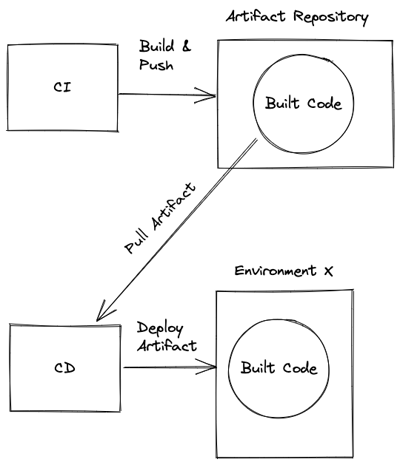
Most environments exist of servers set up to run your applications. The environment can be anything from manually maintained servers to something a little more future-proof such as a Kubernetes cluster running containers. There are two fundamental aspects to all environments, though.
DevOps Engineers always have access to these environments. This access enables them to fix any misconfigurations or problems that may arise. It means these engineers can change the environment manually. But wait, we have pipelines to manage these environments, right?
Yes, but there are a few problems with these pipelines.
Problem 1: Building code and Deploying code are wildly different
Consider the following. CI builds the code. CD deploys the code to an environment. The only input the CD part needs is a code artifact. It can in itself then decide where to deploy that artifact. The only input the CI part needs is the actual codebase.
When we think about future-proof automation we try to keep each step as simple as possible and attempt to let each step in the process only do one thing and do one thing well. Master of one vs master of none.
We can approach our pipelines in the same fashion instead of just a step in that automation. Make a pipeline that is a master of one, instead of a master of none.
Problem 2: Pipelines that do both building and deploying are really complex!
The more responsibilities we give our pipeline, the more complex it will get. The more complex pipelines are, the more difficult it is to actually maintain these pipelines.
The tooling used to build the code and deploy the artifacts is also widely different. Building code requires tooling that understands your code and can run the appropriate steps to test/build/publish that code. That in itself is already pretty complex because you might want logic that fails a build when some testing criteria are not met.
The more you add logic concerning either CI or CD, it inevitably impacts the other. Adding checks for CI means CD can be impacted because of CI failing. Adding CD logic means the CI part can run for no reason, if the pipeline fails at one of the last steps.
So now that we know that pipelines are generally more complex the more we let them do, and they can fail at any of those steps at any time. Let me ask you this: can you, easily and without a doubt, tell me exactly which artifact is currently running on the development environment? For one repo with one codebase this can be done, but can you also tell me this for all 15 applications that make up your business?
Problem 3: Pipelines that only run when code is changed leave environments open for configuration drift
The fact that DevOps Engineers can alter an environment leads to the following. Can you spot what is wrong?
- Pipelines should manage all environments.
- All environments are changeable by DevOps Engineers.
Develop and Production environments are always changing. Even if you first and foremost attempt to do everything via pipelines and from Git, eventually the environment will be altered.
Then when after some configuration drift you push some changes to your repository and the pipeline automatically kicks off. But in the output you suddenly see the dreaded `x amount of resources changed`, but all you did was update the readme. What happened to those 5 resources?!
Problem 4: It's never just one pipeline, it's a collection which leads to difficult insight
Pipelines fail for all kinds of reasons. If you deploy code from a main or develop branch and your business consists of multiple applications working together, let me ask one question:
By looking at the artifact version, can you tell me exactly which code features you are testing when looking at the develop environment?
This usually means looking at all pipelines for all applications and checking which ones failed, which one the last successful one was, and then checking in Git what was actually in there.
The more complex the pipeline and the more pipelines, the more difficult it is to find out exactly what code together is the current development environment.
TL;DR:
So to sum it up:
- CI: Testing and building code, publishing the resulting artifact.
- CD: Taking the artifact and deploying it to various environments.
And what are the 4 problems with CI/CD pipelines?
- Writing code and testing that code is completely different from actually running that code.
- Pipelines that both do CI and CD are much more complex because they need code to deal with both worlds of writing software and running software.
- Pipelines only run once the code is changed, what if the environment itself is also changed. Manually or by any other means. The longer a pipeline is not run, the longer configuration drift can occur. Leading to difficult situations.
- It's never just one pipeline, it's a collection which leads to difficult insight.
Conclusion
If your pipeline does everything, from building the code to deploying the code it can become really complex really fast. Adding new environments comes at the cost of updating all pipelines. Keeping track of what software is running in what state becomes much more complicated and often has you resort to other solutions just to keep track of your platform (Gitlab environments for instance).
In this blog we talked about some of the issues that come up if you're building a pipeline that does all the CI/CD steps. But how do you solve them in an easy to maintain and scalable way?
Keep an eye out for the following blog where I go into a very easy solution to fix all of the above issues! The new blog is out now! Read it here: Splitting CI from CD.



