

In this blog I will be talking about how you can unlock the potential of Kubernetes by focussing on it's API, while trying to avoid the complexities you might encounter. Find out how and if you can make Kubernetes work for you.
A new year: reflection time
As we have moved from 2023 to 2024, it is a good moment to reflect. Undoubtedly, one of the biggest topics of the past year was the rise of AI. But somewhat closer to my day-to-day job, some events stood out:
- The Amazon Prime move from serverless microservices to ‘monolith’ blogpost. Which was followed by a lot of clickbait lukewarm takes and “my tech stack is better than yours” type of discussions. Start at this post by Jeremy Daly to pick some articles worth reading and avoiding about this topic.
- Social media being social media: Debates [1] about pretty much every tech topic, including how “Kubernetes has single-handed set our industry back a decade”, as put in perspective by Kelsey Hightower. Or 37signals’ move out of the cloud, dodging Kubernetes in the process.
- Datadog's outage. Caused by a variety of contributing factors that can be summarized by the keywords: Kubernetes, Cilium, eBPF, Systemd, and OS updates.
- It's all explained nicely by Gergely Orosz (The Pragmatic Engineer).
Working with, and liking Kubernetes, reading all of the above, it's tempting to reflect on the question “What did I get into?". Or in a broader sense: “What have we as an industry gotten ourselves into?".
Discussing the value and cost of Kubernetes in my opinion should not merely be about “servers vs. serverless” or “simple vs. complex”. It should rather be about at what point (assuming that point exists) the benefits of Kubernetes outweigh the challenges.
So, let's focus on where Kubernetes stands, and its strong points and look into avoiding some of its complexities.
In this article:
- A New Year: Reflection time
- Versatility
- Why and how
- Building a skyscraper
- Focus: Not everywhere at once
- Complexity budget
- API Flywheel effect
- API mindset
- Conclusion (aka TL;DR)
Acknowledgement: Some vendor names or logos appear. I'm paid by none and none are to be interpreted as recommendations over similar solutions that might exist.
Versatility of Kubernetes
Kubernetes is everywhere: it can facilitate a variety of workloads in a variety of environments:
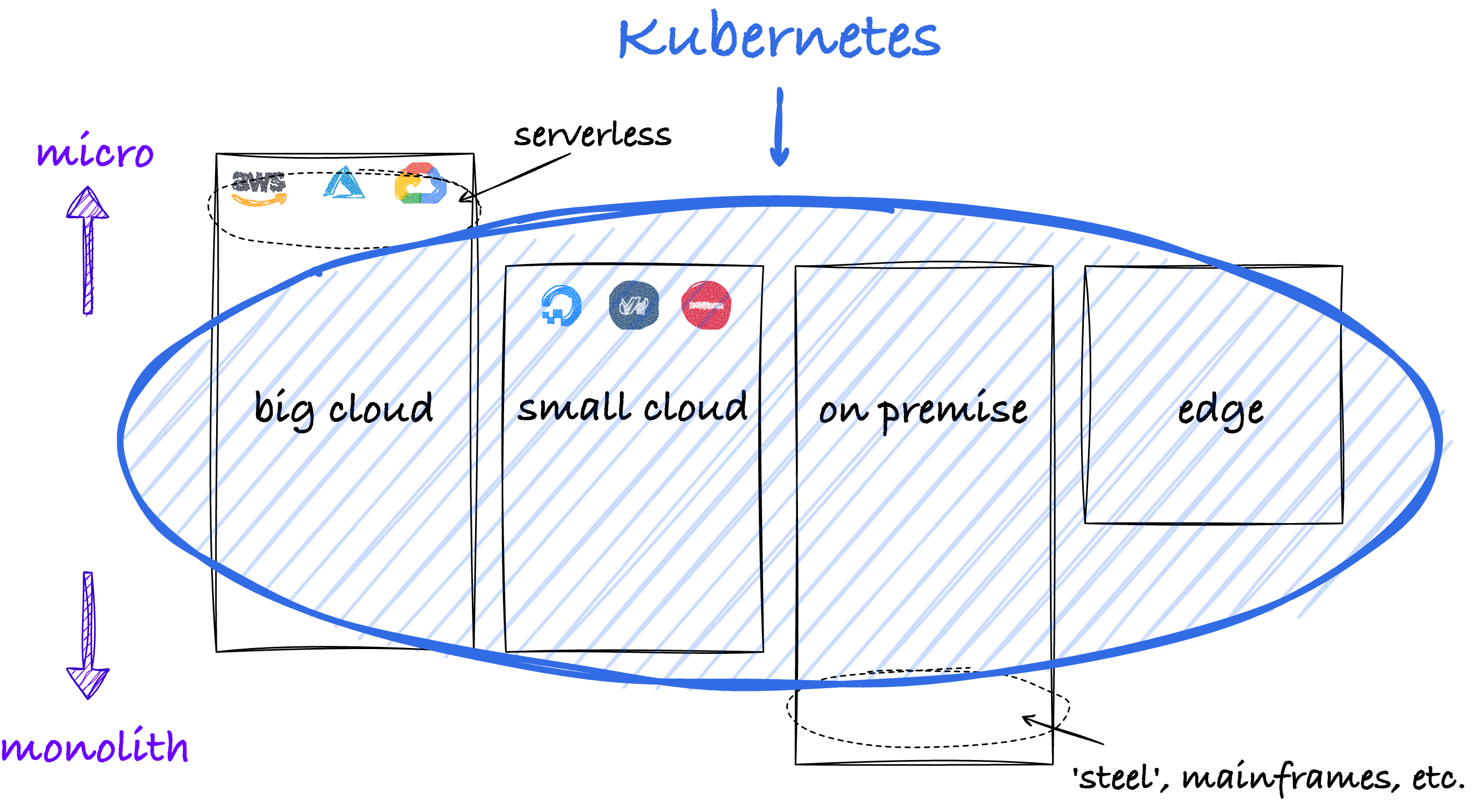
KUBERNETES IS EVERYWHERE
As seen in the above diagram, Kubernetes can run in environments ranging from big clouds, small clouds, on-premise data centres to edge computing.
Focusing on the different types of workloads, Kubernetes can do a lot. But there are types of workload Kubernetes might not be particularly suited for. On the monolith side, one could think of (legacy) mainframes. Or VM-based applications that are hard to containerize.
The big cloud platforms offer a plethora of managed services, including databases, memory stores, messaging components and services focused on AI/ML and Big Data. For those, you can run cloud-native cloud-agnostic alternatives within Kubernetes. However it requires more up-front effort, and the potential gain will differ per situation.
Then on the far end of micro, big clouds offer ‘serverless’: Function-as-a-Service, typically well-integrated with components like an API Gateway and building blocks for event-driven architectures. One could decide to run those in Kubernetes, for example, using Knative. But it requires setting up and supporting those components first, whereas the cloud in that regard is easier to get into. Additionally, serverless offers fast scaling and scale-to-zero as a distinguishing feature.
Kubernetes can provide its users with a standardized way of working (roughly: Put YAML [2] in a cluster), and platform teams [3] a unified way to support engineering teams (roughly: Help come up with proper YAML and help put YAML in a cluster). And it can do so by leveraging and integrating the managed services of big clouds, instead of trying to replace all of them.
More on that standardization later.
Why and how to use Kubernetes
As an organization, it is important to have a good understanding of why a (technical) strategy is chosen and what the expectations are.
As the title of this blog post suggests, it's good to have a clear answer to the question “Why are we using Kubernetes?". But perhaps even better would be if “Kubernetes” is the logical answer to various challenges faced by an organization. For example:
- How can we effectively run numerous containerized workloads?
- How can we allow a team of cloud specialists to empower many engineering teams by providing golden paths and guardrails?
- How can we run applications at the edge, preferably in a way that aligns with the software delivery process we already have?
- How can we allow engineering teams to deploy applications in our on-premise data centre?
- How can we standardize our way of working while providing flexibility where it matters to us?
- How can we ensure the know-how and tooling we invest in, are as widely applicable as possible (e.g. not limited to a single cloud vendor)?
Yes, the last point has this ‘multi-cloud’ and ‘vendor lock-in’ ring to it. To be clear: Switching clouds because computing is a bit cheaper elsewhere, hardly ever pays off. Using the common denominator of multiple clouds, just to be ‘multi-cloud’, hardly ever pays off. Vendor lock-ins are everywhere, not just at the cloud selection. But, looking at the timespan of years, an organization might see an advantage in focusing on technology that is applicable across vendor boundaries.
Building a skyscraper
Embarking on the journey to adopt Kubernetes, there is a lot that needs to be set up before Kubernetes starts to deliver value. We are building a platform. Let's illustrate by a physical-world-building analogy:
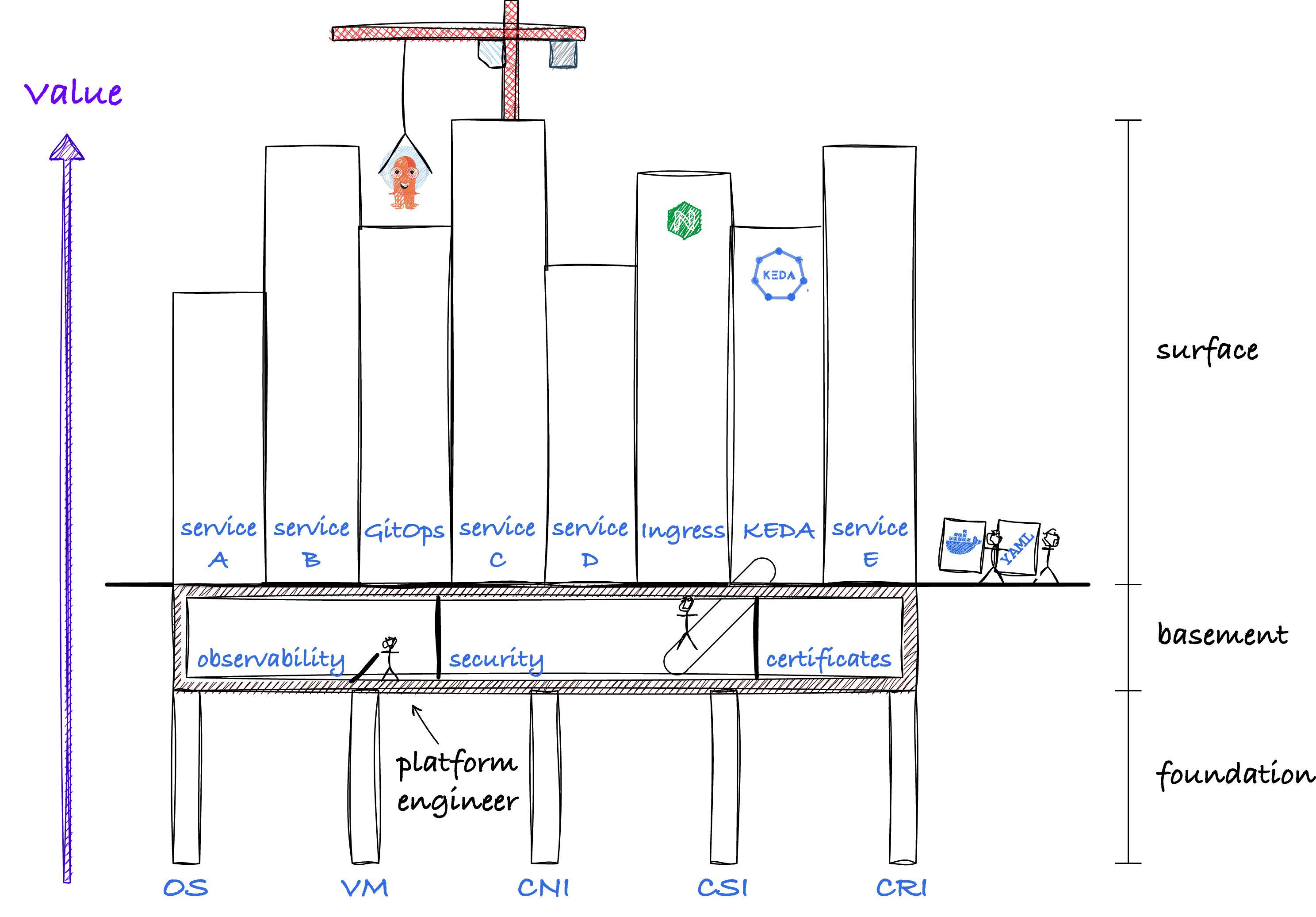
BUILDING A PLATFORM
At the bottom, we find the foundation. It's there because it needs to be there, but nobody builds a foundation just to have a foundation. In Kubernetes terms, the foundation includes components like networking (CNI), storage (CSI), container runtime (CRI), virtual machines or bare metal servers and operating systems.
Next up is the basement. Similar to the foundation, this is not the end goal (unless you're building a parking garage with a park on top). It houses things that need to be there that you typically take for granted: equipment, maintenance rooms, piping and whatnot. In Kubernetes, this translates to some basic requirements needed before going live: Observability and security. Certificate management. Perhaps a policy engine.
Finally, we get above the surface. This is what we are building for: Buildings that have a purpose! In Kubernetes terms, these are obviously the applications that are deployed. But also components that enhance the ability of our platform. Examples include ArgoCD/Flux (efficient deployments using GitOps), Argo Workflows (Workflow engine) and KEDA (smarter scaling).
Now for each component, one could argue if it's the foundation, basement or building. Perhaps ArgoCD and KEDA are more basement than building. Maybe CSI is also basement, instead of foundation, since you can somewhat easily add or remove storage classes.
What matters is that going from beneath to above the surface, we can observe the components:
- Become increasingly visible
- In general, become easier to adapt over time
- Change from being just cost to something that delivers value
Focus: not everywhere at once
An organization needs to be careful not to get caught up spending the majority of its time on foundation and basement while lacking resources to put up something nice above the surface.
At the same time, you can only build on top of a solid foundation. And the basement should not collapse either.
We need focus. If running in one of the big clouds, all the foundation components exist in a prefab way. We should consider those first.
Similarly, at the basement level, we can spend a lot of time building an observability platform. However there are various SaaS solutions or solutions provided by the cloud provider. Likewise for security. If prefab components don't satisfy a requirement, carefully review those requirements. Are we sure the proposed simpler solution is not ‘good enough’? Can we settle with something simple now with the option to improve later?
When running on edge, focusing on the operating system and networking is essential: We need the ability to safely update the remote device without breaking networking and locking ourselves out. On the other hand, when running in the cloud, favor the solutions provided by the cloud vendor and leave it at that.
When running on premise, we probably need a performant storage solution and backup solution for stateful workloads. But when running in the cloud, we do not need to DIY databases in Kubernetes. Consider a managed database, providing all the sizing options and point-in-time recovery you need. Use S3-compatible object storage for storing files. Use a SaaS for observability, avoiding the need to store all those logs, metrics and traces. Doing so allows storage requirements to be minimal, allowing our set-up to stay simple.
Complexity budget
Any customization or component added to a cluster adds complexity. It requires day 1 set up and day 2 maintenance and by that, it requires resources. This means there is a budget for the amount of complexity we can sustain.
While boundaries of definitions might vary depending on who you ask, we could consider every customization or addition to our platform capital expenditure: It's an upfront expense we expect to get a return on investment (ROI) out of.
As long as what we spend on CapEx results in reducing, or at worst, stabilizing our overall operating expense, our operations are sustainable. If not, and OpEx gets the upper hand, we run into problems.
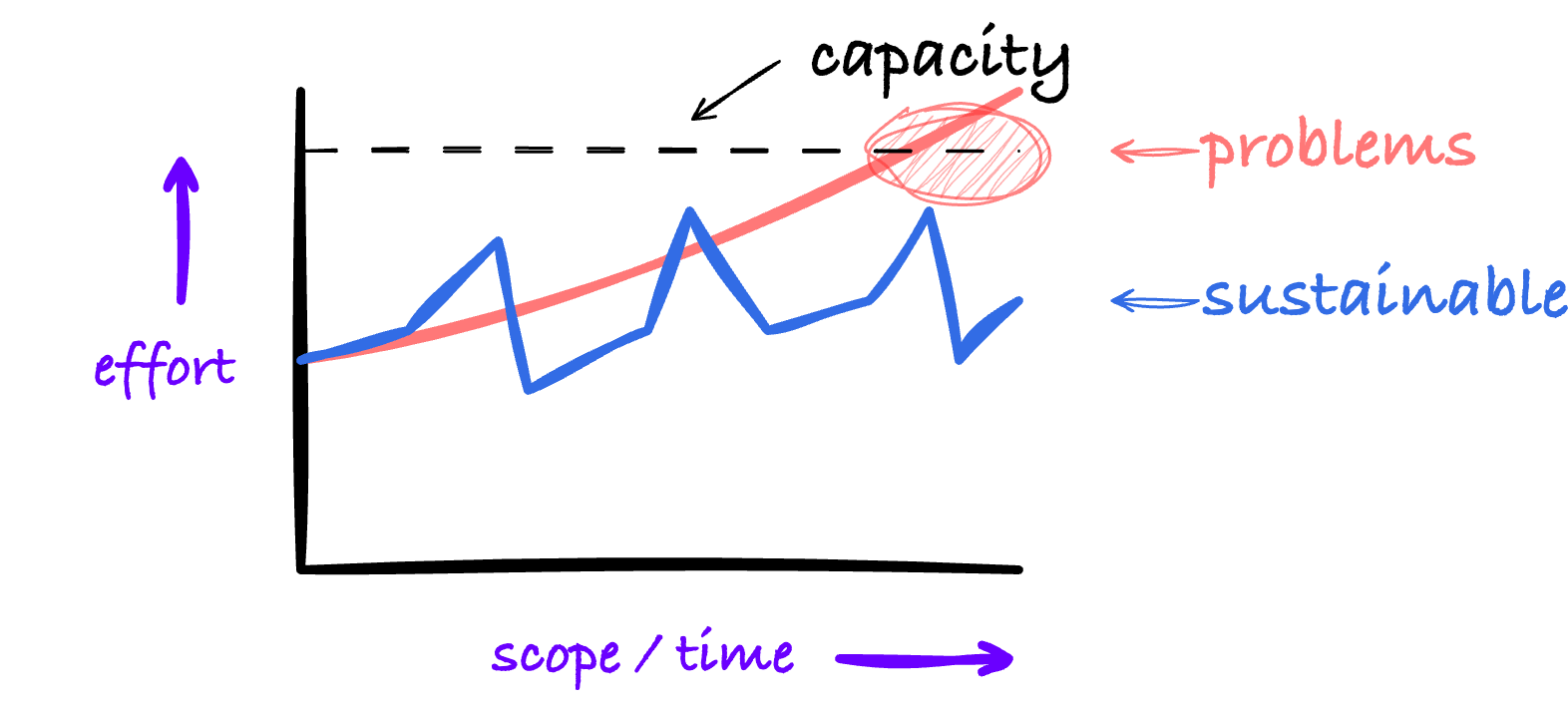
CAPACITY
This does not mean that we should never add any component to our platform. When the scope of our operations increases, complexity increases as well. We need ways to deal with that. This is not unique to Kubernetes, by the way.
It does mean that we should consider when is the right time to add components and what their effect on the overall effort will be, going forward.
API Flywheel effect
When having dodged some of the complex rabbit-holes beneath the surface, the unified API and way-of-working Kubernetes provides, can start to pay off. Let's illustrate:
Challenge: We have a Kubernetes set-up. Teams are deploying applications. However, we notice workloads are sometimes not resilient to rescheduling. Also, consistent tagging is a bit of a problem.
Improvement: We add a policy engine. This helps us enforce good practices.
New status: The team put YAML in a cluster. Cluster occasionally says NO.
Challenge: We notice we start to have a lot of deployment pipelines. And they are all slightly different. And we find it increasingly hard to correlate what is supposed to run in our cluster, with those pipelines, that are primarily managed by various engineering teams.
Improvement: We add GitOps. We now have a single pane of glass, with a pull-request-based workflow to deploy updates. PR-based workflows we already had, so that is a good fit. And of course, we can automate certain updates to avoid unnecessary pull requests. Also worth noting is that by splitting CI and CD pipelines, our pipelines can become a lot simpler.
New status: Team puts YAML in git. GitOps puts YAML in a cluster. Cluster machinery makes things happen.
Challenge: Some teams notice they need something more ‘clever’ than CPU-based scaling of workloads.
Improvement: Platform team sets up KEDA. Since there's already a policy engine, it is easy to set up some guardrails for KEDA scaler configurations.
New status, just like it was previously: Team puts YAML in git. GitOps puts YAML in cluster. Cluster machinery makes things happen.
Challenge: The platform team notices that a lot of the changes that need to be done for engineering teams boil down to the same: Provide a namespace, an artefact repository, a database, Redis, a pipeline, IAM identities for new services or a queue.
Improvement: After a POC, the platform team decides to set up Crossplane, adapt the policy engine to allow a curated set of Crossplane resources and provide guardrails. Now teams can set up the resources themselves. The platform team meanwhile, can continue to focus on providing and maintaining that capability, without getting swamped by ‘lots of similar tasks’.
New status, just like it was previously: Team puts YAML in git. GitOps puts YAML in a cluster. Cluster machinery makes things happen.
Challenge: The platform team notices it takes increasing effort to keep track of component updates.
Improvement: After a POC they set up Renovate. Now, the platform team no longer has to check the release pages of each component that is running on the platform.
New status, very similar to previous: Renovate puts YAML in git. GitOps puts YAML in the cluster. Cluster machinery makes things happen.
The changes described above are not something implemented overnight. Furthermore, they sometimes involve changing the way of working in an organization, which usually, compared to the technical part, is the hardest part. They do show, however, how carefully taking on additional complexity in one place, can reduce the overall operational effort within an organization.
API mindset
When adopting Kubernetes, depending on organization, experience and culture, there might be different perspectives:
- Server-up: “We run servers, and we put Kubernetes on top of them”
- API-down: “We run Kubernetes, and we just happen to need servers for that”
The former tends to lean towards avoiding change and focus on uptime.
The latter embraces frequent controlled change as a means to keep fulfilling various requirements.
It's a subtle difference but, as you might have guessed, the API-down mindset is a better fit when using Kubernetes. It will result in a platform that is easier to maintain in the long run. Some examples:
Instead of: Set up shell access to servers for administrative purposes.
Do: Focus on how to avoid ever needing to log in to (production) servers. What observability data do we need to send out? How can we reproduce error scenarios in a lab setup?
Instead of: Investigate how to patch nodes in place, with all the orchestration, checks and reboots that come with it.
Do: Consider immutable infrastructure. Simply replace nodes with patched ones frequently. A process that is easily reproducible (testing on non-prod) and reversible. Bonus benefit: Chaos engineering.
Instead of: Using Ansible to ‘do things on servers’
Do: Focus on immutable infrastructure, and cloud-init to perform the few absolutely necessary installation steps.
Instead of: Extending VM images with observability agents, EDR agents and whatnot
Do: Favor daemonsets [4], having security context as needed, to run those processes. Remember the flywheel effect: We already have means to easily put workloads in clusters, and all the observability in place to monitor the components. Also, Renovate will help us to keep the components updated.
The takeaway of the above is that we need to avoid ending up what we did a decade ago (managing a fleet of VMs), plus managing a lot of Kubernetes moving parts. We need to leverage Kubernetes to make the VM managing part much easier or disappear entirely. That will leave room to focus on the platform and developer experience.
Conclusion (aka TL;DR)
At a certain scale, and as the number of teams increases, organizations will face the following challenge:
How to provide guardrails without ending up with gates?
Topics like compliance, security, cost-effectiveness, performance and disaster recovery all need to be addressed. Delegating that to each individual team is not efficient: For teams, it's a distraction, and it requires having sufficient knowledge of those topics in each team. As a result, organizations need a way to consolidate this knowledge and apply it to all teams. This in a nutshell is why the buzzword ‘DevOps’ is nowadays superseded by ‘Platform engineering’.
Running at scale, Kubernetes, also in 2024, can be a suitable stack to build this platform engineering on top of. But the stakes are high: There can be great rewards, but it requires upfront effort before it starts to give back. That imposes a certain risk and a barrier of entry.
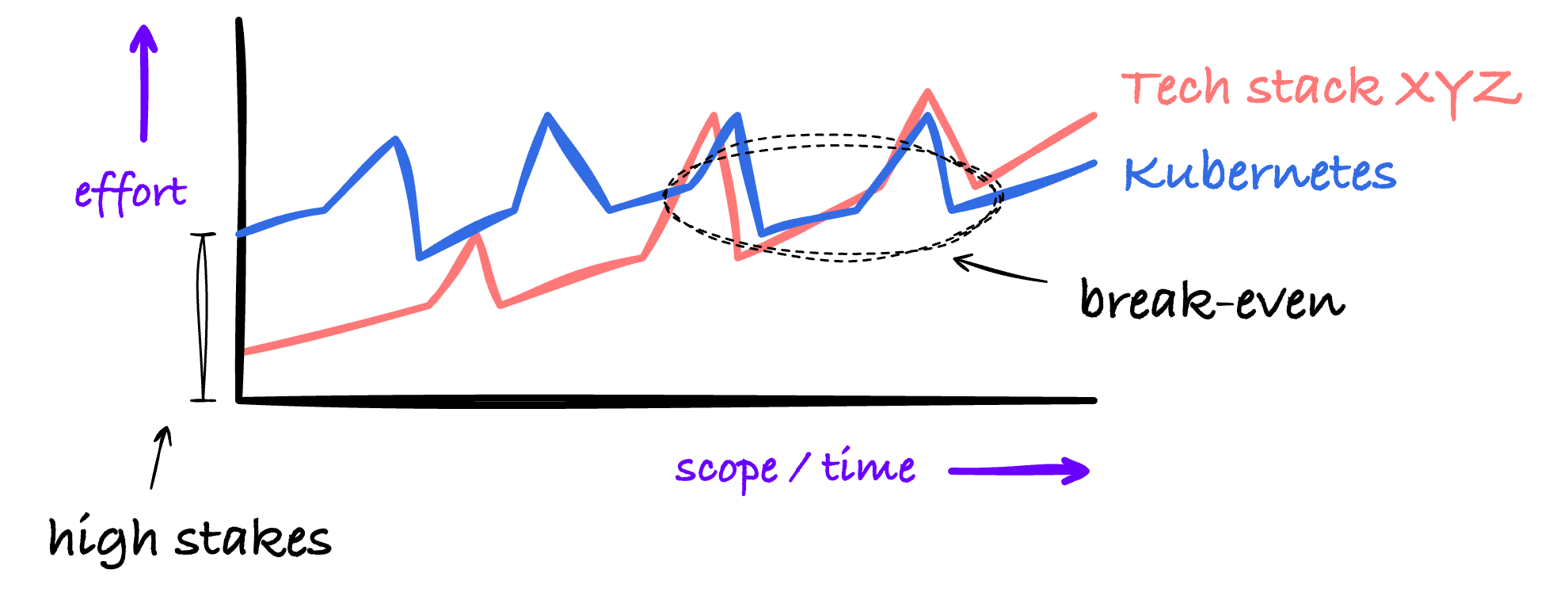
COMPARING TECH STACKS
As the above diagram shows, between technology stacks, a break-even point exists. Do note that this is a generalization: If and where that break-even point exists, depends on if an organization succeeds in tackling the challenges of keeping the overall effort within limits. The takeaway is that Kubernetes, by its nature, is well-suited to scale out the initial effort to many teams.
When not focusing primarily on scale: Running at the edge, Kubernetes might turn out to be an interesting choice that integrates naturally into the way you operate your centralized applications.
However, Kubernetes might simply not fit your organization:
- Startup needing to run ‘some’ applications in the cloud? Don't build Kubernetes first unless you have a clear goal for that.
- Autonomous teams without centralized platform teams? You need something to prevent every team from re-inventing slightly different DevOps wheels. Could be Kubernetes.
- Not running that many containers but using serverless? Fantastic, set up your organization to continuously improve that stack. Don't consider Kubernetes because ‘people are using Kubernetes’.
Spend your complexity budget wisely. When choosing Kubernetes, focus on the API and you might even forget about the servers.
Just avoid getting caught up below the surface while forgetting to enjoy the sunlight.
------
- Avoiding bubbles, and filtering out noise and engagement-farming lists of random things, there are still a lot of insights and perspectives to get from social media.
- Luckily there are enough tools these days to satisfy anyone's preference for plain YAML, templated YAML, programmed YAML or JSON converted to YAML.
- Where I mention ‘platform teams’ or simply ‘teams’, looking at Team Topologies, they refer to ‘platform teams’ and ‘stream-aligned teams’ respectively.
- Guilty, been there. Extending AWS AMIs is totally cumbersome compared to managing a daemonset.



